
Using another metadata standard than MARC21 in VuFind, Part I
Contents
Introduction
When you install the open source discovery system VuFind, follow basic configuration steps and feed it with library records, it works well out-of-the-box and provides you with faceted search results and the possibility to browse through your data besides many other features. The easiest way to achieve this, is to load the standard interchange format for library records, i.e. MARC21, into the included Apache Solr-based search index. The FID Performing Arts uses VuFind since 2015, but as mentioned in an earlier post, we receive a vast amount of metadata from performing arts museums and archives in standards other than MARC21, such as EAD, METS/MODS and LIDO as well as other individual data formats which result from database systems like MS Access or FAUST DB. In order to meet the special requirements of performing arts metadata and work with a consistent data set during data aggregation, we decided to map all received data into an extended version of the universal and flexible Europeana Data Model (EDM).
VuFind provides the possibility to index other metadata standards than MARC21 and even supports several standards next to each other in the same VuFind instance. It supports multiple search backends as well as using so-called Record Drivers and combined searches. Though we decided to use only one standard within VuFind. This is with regard to being able to make adjustments to the data during preprocessing, mapping and enrichment and to make the data more independent from the software used to display it. This two-part blog post series describes the steps you need to take to support a new RDF-XML based metadata standard like EDM with a Solr search backend in VuFind. You can find all code in our fork from the main repository on GitHub.
Following the path of data in VuFind
There is much to learn about VuFind and Solr and we won’t be able to give you a thorough introduction of all details and features here. Please note, there is great documentation, a book and video tutorials for VuFind and Solr documentation if you want to learn it from scratch. Also, this post was written in regards to VuFind 8.0 with Solr 8 and the necessary steps might be slightly different in other versions.
Since VuFind is open source and very modular, you can modify it to your needs simply by changing configurations without even touching any code. However, for our use case, we need to make changes to the code in order to support the new metadata standard, so we need to know the way the data takes within VuFind.
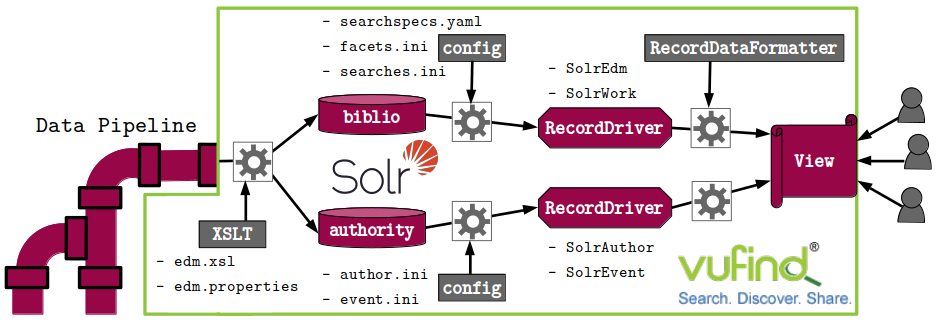
(Fig. 1: The path of the data within VuFind.)
For our purpose, we still want to use the power of Solr as a search backend (for external backends consider this page) and re-use as much of VuFind’s existing code as possible. So we first need to map the records to Solr’s XML document format and index them into Solr by using VuFind’s import helpers and make adjustments to the provided Solr schema. This is covered in part I of this blog post. In part II, we will describe the changes to configurations that give VuFind instructions on how to cope with the new record format. The implementation of new RecordDrivers allows us to interact with the indexed data and chooses the correct templates for displaying the records with support of the so-called RecordDataFormatter. Finally, other features like recommendations and record export are discussed.
Indexing EDM-XML data into Solr
Solr cores and index schemas
Solr holds multiple cores, each take documents with sets of key-value pairs to which Solr applies faceting and filtering rules. Without going further into the details of EDM, the important thing here is to note that EDM consists of classes of interlinked entities. As an example, we can describe that a person created a resource like a costume that was part of a performance event which is a realization of a work. We use two Solr cores to represent these different types of data:
- The
bibliocore stores title data which in case of EDM is the cultural heritage object (edm:ProvidedCHO) like a playbill or photograph in combination with the information from the aggregation (ore:Aggregation) such as the data provider, right statements and links to digital copies. We further store records from the authority type work in thebibliocore as they usually have very similar properties as textual resources in library records. - The
authoritycore stores authority data which in case of EDM is the data of the classes person (foaf:Person), corporate body (foaf:Organization), event (edm:Event), place (edm:Place), time period (edm:Timespan) and concept (skos:Concept); we are currently only implementing the first three classes in VuFind though.
Both Solr cores have their respective schema.xml files in VuFind’s solr/ folders that define record fields, their types and filtering rules that apply. You can find the explanation of the current versions here and here. So after harvesting, preprocessing, aggregating and enriching our data in the data pipeline, we map it from EDM-XML to Solr XML documents like the following that conform to these schema files:
|
|
The most important field from the schema that we need to populate in our Solr XML documents is id to provide Solr with a unique identifier for each record. Solr will overwrite records with the same id, so be aware of that when re-indexing. Another important field is record_format which tells VuFind what format this record has and which RecordDriver to choose. This is especially helpful if you have records coming from different data pools with different formats. We also populate the fullrecord field because it helps us displaying data that won’t be part of the search but instead is only relevant for display. By re-using as many of the fields in the given schemas as possible, we keep maintainable code with only little changes during updates and can re-use many VuFind methods and templates like the ones for displaying hierarchical records from the main code base.
|
|
For EDM, we needed among other fields a date span field with a date range to be able to represent time periods like festivals. As shown above, we further added the multivalued fields event and work to schema.xml of the biblio core by following the way authors are represented in VuFind to easily find events and works related to the given resource. Additionally, supporting EDM’s linked data approach, we added _id fields to be able to search for persons, events and works not only by string labels but by an identitifer to be sure to find the correct related entity. This is useful for persons or events with the same name which happens quite a lot through the centuries of performances that are based on well-known works. For that, we followed the same approach as VuFind does with author_role, where order is important for knowing which entries belong to each other. Note that the id fields are not only indexed but stored in Solr, because we wanted to retrieve these ids also for display and other functionalities. If you make changes to the schema files later on, don’t forget to re-index your records.
XSLT Import
VuFind provides a mechanism for indexing XML records to Solr, so we can re-use the existing batch-import-xsl.sh which first maps records via XSLT into Solr’s XML format and then imports record batches into a Solr core. However, we cannot re-use custom methods for formatting and other features that come with the included SolrMarc package. Additionally, we are not re-using one of the existing XSLT either, because PHP only allows the usage of XSLT 1.0 which makes the whole process a bit inconvenient if you have to do most of the mapping yourself. Instead, we map the records outside of VuFind with the power of XQuery and XSLT 3.0 (see also this blog post on XSLT) and only use a tiny XSLT 1.0 script within VuFind. We can use it for both title and authority records, because it mainly does an identity transformation and outputs the given XML as is:
|
|
The only other template in this XSLT script uses a VuFind function to populate the fullrecord field with raw XML input as text. Another interesting function in this context, though we currently don’t make use of it, is VuFind::mapString which you can use to map strings by means of a configuration file from VuFind’s translation_maps folder.
|
|
Custom files and overwrites to existing VuFind files are placed into the local/ folder. So we add the XSLT in local/import/xsl/edm.xsl and then we also add local/import/edm.properties which sets the XSLT to use during import with batch-import-xsl.sh and which PHP functions are used. In the properties file, you can also define parameters for your XSLT.
|
|
Then you can start the indexing with:
|
|
It is recommended to use the batch record mechanism with collections of records as this is way faster than importing single records. For testing and troubleshooting, you can also do single imports with import-xsl.sh that can help you identify problematic records, even if it’s slower, or use the --test-only flag.
To be continued
Now that your records are indexed in Solr, we will proceed next month in part II of this series when we will learn how to make the new format visible in VuFind.
Last Modified on 2023-02-06.