
Data Engineering with luigi - Lessons learned
Contents
Introduction
At the UB JCS, we make extensive usage of the Python luigi framework for data engineering. The framework is capable of handling thousands of tasks, calculating non-circular task dependencies, and run over days. Additionally, it provides a convenient web control panel to see, e.g. the task dependencies in a tree diagram or start specific tasks.
Although luigi itself supports the user already by enforcing a very specific structure, there are still some things to consider when designing a data pipeline with luigi (for a general introduction, see in a previous post). In this post, I present ideas, that I learned while using luigi. Since luigi is a heavily object-oriented framework, some approaches in this post rely naturally on Software architecture patterns.
What would Mary Kondo do?
Although with luigi we are in the field of data science / data engineering, we still have to think like a programmer (or at least a little like Mary Kondo) when structuring our code. Hence, we want to have everything clean, separated, and modular.
After some years of working with luigi, I worked out a luigi project structure that looks like this:
|
|
Of course, this is only the top-level structure. You are free (and encouraged) to further nest the given directories. And even if the project is still growing, with luigi and the given structure, it should be easy in the development process to push around files with only minor changes of the code.
The idea is that a task can call functions that are provided in scripts. However, only tasks import classes (e.g. factories, DAOs, serializers, abstract classes), initialize them and provide the initialised objects to a script (Fig. 1).
This structure allows to keep the details within the classes and use a common interface class to call different implementations of a common process. For example, each class could be a different data provider and the interface method collect_data() will gather the data from each data provider. But whether the data comes from a file or is crawled from the web, is left to the data provider class – the calling script is not aware of this. The interface only guarantees that the result will obey a specific format (e.g. a list of messenger objects). So you can add or remove new classes easily.
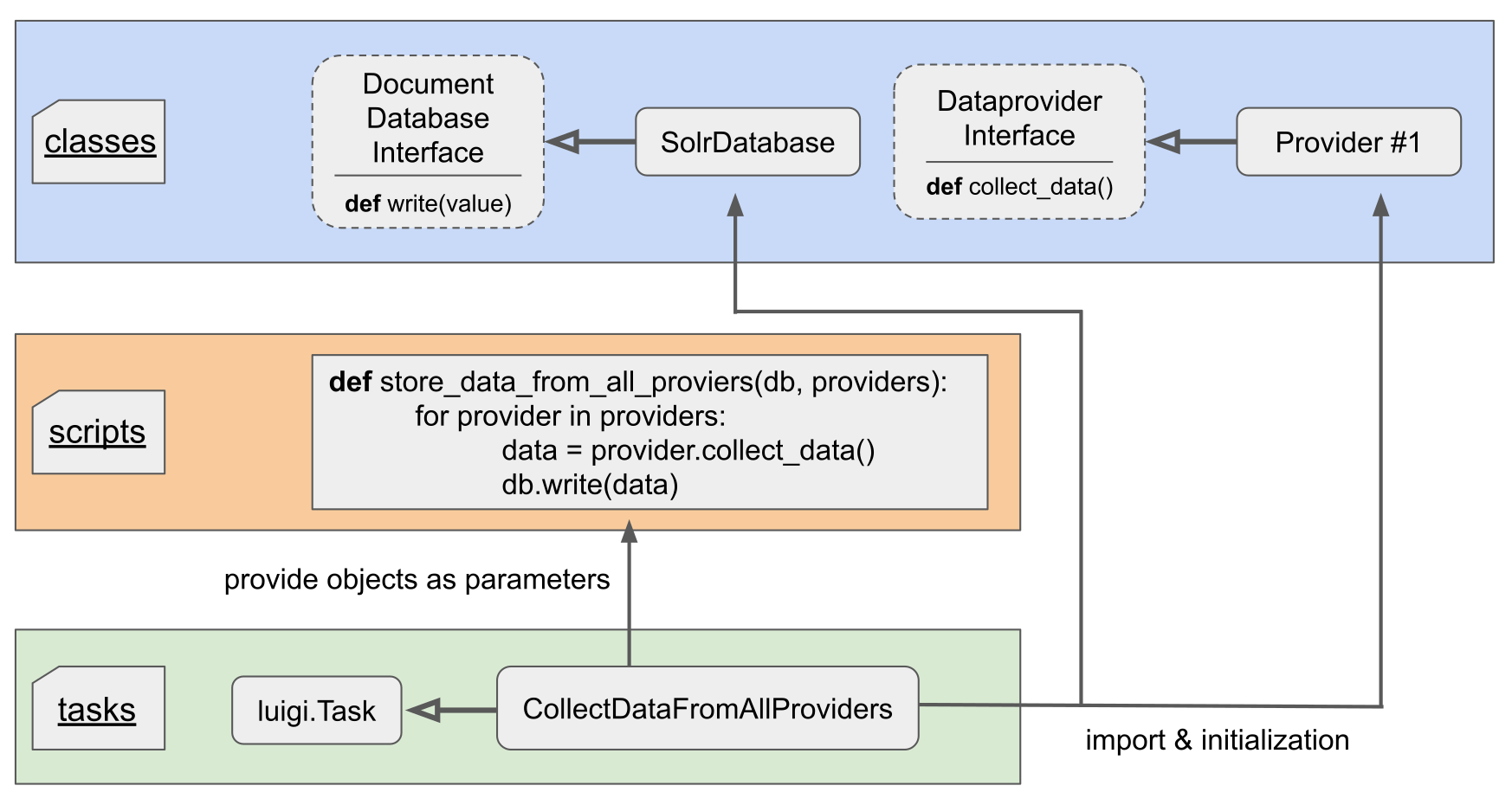
Fig. 1: Separation of concerns in a fictional luigi task.
My recommendation follows the src project structure1, since it provides a nice separation of concerns in regard of code (everything in the src folder) and project management (pyproject.toml, tests, etc.). This structure has the “downside” (depending on perspective) that the code has to be installed before usage, which would not be necessary in a flat hierarchy. On the other side, the src structure assures that the tests only run on the code that is installed and you do not commit a broken package.
What are a task’s responsibilities?
The main interface that luigi provides are its tasks. A task is one step that does a specific job (like downloading a data file, iterating all data in a database, etc.). The three main responsibilities of a task are very nicely depicted by its three main methods: requires(), run(), and output(). So, a typical task may look like this:
|
|
Here, I will cover only my thoughts on requires() and run().
Manage resources
A task’s first responsibility is to manage all resources necessary for the process to run. This does mean that it first makes sure that all depending tasks in requires() have run. This also means that it gathers data, e.g. provided by the configuration. This does not mean that it aggregates the resources by itself!
The task knows where to look for the resources and provides them to the processes in the run() method. Making sure that a data file is at some place on the disk or that a database is filled, is the responsibility of the depending tasks (in the requires() method). I recommend to be very granular when creating required tasks, because:
- If a task fails, a rerun will again process everything in
run(), while a once completed tasks stays completed - Other tasks may also depend on the same resource(s) (i.e. tasks)
- It scales much better
Delegate the job
A task may lack both methods requires() and output(), but having a task without run() is rare (but can be useful). So, what should run() actually do? It is not running the job! The responsibility of the run() method is to delegate the job to the script that does the actual job. The script does its work and, when it is done, it returns back to the task. Whether the script returns a value or not, depends on the situation. Hence, the run() method orchestrates the job, it does not perform the actual work itself.
Additionally, the run() method also has to use the aggregated resources of the task to provide the script with the necessary input arguments. This approach implies that run() provides simple parameters like paths to data files or a dict to process. More importantly, the run() method should also provide more complex structures like database objects to the script. The creation of the database connection should never be in a script, but the script should instead rely on dependency injection (DI). DI grants the code more flexibility and reduces the cost of change.
DI enforces a design in which a script does not rely on a specific class but on an abstract interface. If you, at some point in the development process, decide to change the database for a specific task, you can simply change it in the task, while the script does not care about the change – it still works. Of course, this requires a level of abstraction in your class design, but decouples the code strongly.
Use a central configuration
In many instances of the luigi documentation, you will see that tasks define their own configuration parameters like so (from the luigi documentation):
|
|
This may be useful in some cases, but applied in general, it becomes a mess very fast. Hence, I recommend to have configuration files in a configurations folder. A configuration file may contain one or multiple luigi configuration classes that handle all the data input from the configuration file.
Example configuration in a file src/configurations/general.py:
|
|
Using the property decorator in a configuration class allows you to orchestrate resources both in a central position and in a dynamic fashion.
In the example above, I put all configuration classes into a single configuration file. However, I recommend to separate them into multiple configuration files with meaningful names. In this case, it would make sense to put the two classes DocumentDatabaseConfiguration and GraphDatabaseConfiguration into a file src/configurations/databases.py.
With this approach, all your configuration lives in one place, and tasks can use it very conveniently:
|
|
Let luigi send you (lovely) messages
You can configure luigi to notify you via mail, if a run fails. This allows you to react immediately and fix the problem. This is the most obvious way to use luigi’s notifications.
Additionally, luigi allows you to send messages e. g. on successful runs. This makes especially sense, if luigi is triggered by a cron job. After luigi completed a specific task, it will notify you via mail – giving you the warm feeling that you are a mastermind of automation.
You can trigger the notification dispatch by using the on_success() method of the Task class:
|
|
You want to use on_success() (or on_failure(exception) to handle failing tasks) for sending notifications. There is also a method named complete(), but that is called by the luigi daemon to check before running the task, if the task needs to be run or not.
Be aware that you are not restricted to get mails. When importing e. g. the slack_sdk package, you can setup notifications via Slack.
Although in this example luigi’s send_email_smtp is called directly, I recommend to define a function in a file like src/tasks/commons.py to handle the reusable parts.
Aggregate tasks into groups
If you have multiply independent task working towards a common goal, it may come in handy to gather them in a luigi.WrapperTask. Let’s say, you have a machine learning task that depends on multiple other tasks that gather the data. You can then aggregate these required tasks in a common task:
|
|
This is a valid task that can be referenced by another task as requirement. The luigi.WrapperTask will successfully complete, after all its depending tasks are completed.
Have some tests to check for circular imports
When writing luigi tasks and distributing them in multiple scripts, it can happen quite fast that luigi raises exceptions, because of circular imports. To check for this circumstance in your development environment and not in production, you should have at least a test for circular imports (but you should write tests for all your scripts and classes anyway).
This test only needs to import your main module that start your pipeline. For example, let’s assume, we have the luigi starting task in a file named run_luigi.py. A test for circular imports would look like this:
|
|
When running the test, all imports will be done recursively and any circular import will cause an exception. The test should run in less than an second and saves you a lot of frustration.
Conclusion
I hope, I could give you some new ideas of how to work with luigi and how to apply its myriads of possibilities. If you have questions or comments, do not hesitate to contact us via ublabs@ub.uni-frankfurt.de .
-
For more details, please see https://packaging.python.org/en/latest/discussions/src-layout-vs-flat-layout/, but also be referred to the Python Sample Project. And if you really want to go into the rabbit hole, see the Stack Overflow discussion. ↩︎
Last Modified on 2023-08-17.